Our AAMAS’21 paper on loss bounds for influence-based abstraction is online.
In this paper, we derive conditions for ‘approximate influence predictors’ to give small value-loss when used in small (abstracted) MDPs. From these conditions we conclude that that learning such AIPs with cross-entropy loss seems sensible.
Category: research
NeurIPS camready: MDP Homomorphic Networks
In this work we show how symmetries that can occur in MDPs can be exploited for more efficient deep reinforcement learning.
NeurIPS Camready: Multi-agent active perception with prediction rewards
This paper shows that also in decentralized multiagent settings we can employ “prediction rewards” for active perception. (Intuitively leading to a type of voting that we try to optimize).
NeurIPS Camready: Influence-Augmented Online Planning
The camready version of Influence-Augmented Online Planning for Complex Environments is now available.
In this work, we show that by learning approximate representations of influence, we can speed up online planning (POMCP) sufficiently to get better performance when the time for online decision making is constrained.
Three papers at NeurIPS 2020
Three of our papers were accepted at NeurIPS. For short descriptions, see my tweet.
(Updated) arxiv links will follow…
Plannable Approximations to MDP Homomorphisms: Equivariance under Actions
If you need meaningful latent representations for MDPs for e.g. planning or exploration, have a look at our AAMAS 2020 paper. We use a contrastive loss to learn MDP homomorphisms.
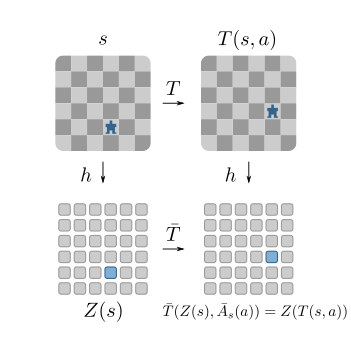
An MDP homomorphism is a structure-preserving map from an input MDP to an abstract MDP (the “homomorphic image”). MDP homomorphisms maintain the optimal Q-values and thus the optimal policy.
Roughly speaking, we find a smaller abstract representation of our MDP, and if the map is an MDP homomorphism, the optimal policy is guaranteed to be the same.
We prove that as the loss function reaches 0, we find an MDP homomorphism for deterministic MDPs. This is attractive because we could in theory plan in a reduced MDP and lift to the optimal policy in the original, bigger MDP!
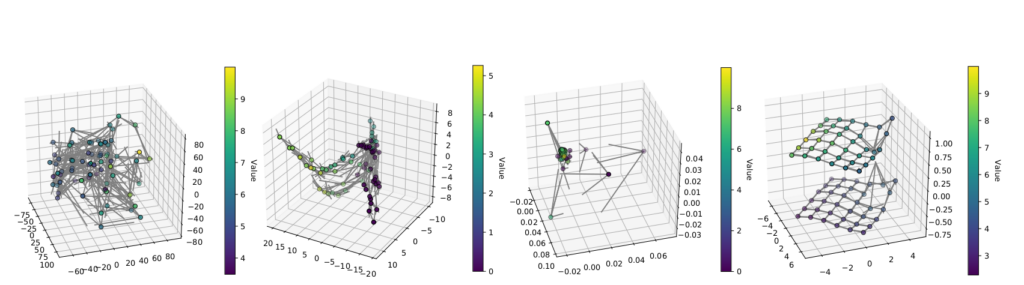
Due to the homomorphism constraints, we learn much better structured representations (rightmost figure), which support better planning. We show empirically that the policy found in the abstract MDP performs well in the original MDP.
Influence-Based Abstraction in Deep Reinforcement Learning
Scaling Bayesian RL for Factored POMDPs
Reinforcement learning is tough. POMDPs are hard. And doing RL in partially observable problems is a huge challenge. With Sammie and Chris Amato, I have been making some progress to get a principled method (based on Monte Carlo tree search) too scale for structured problems. We can learn both how to act, as well as the structure of the problem at the same time. See the paper and bib.
Video Demo with ALA submission ‘Influence-Based Abstraction in Deep Reinforcement Learning’
On this page, we show some videos of our experimental results in two different environments, Myopic Breakout and Traffic Control.
Myopic Breakout
The InfluenceNet model (PPO-InfluenceNet) is able to learn the “tunnel” strategy, where it creates an opening on the left (or right) side and plays the ball in there to score a lot of points:
The feedforward network with no internal memory performs considerably worse than the InfluenceNet model:
Traffic Control
The Traffic Control task was modified as follows:
- The size of the observable region was slightly reduced and the delay between the moment an action is taken and the time the lights switch was increased to 6 seconds. During these 6 seconds the green light turns yellow.
- The speed penalty was removed and there is only a negative reward of -0.1 for every car that is stopped at a traffic light.
As shown in the video below, a memoryless agent can only switch the lights when a car enters the local region. With the new changes, this means that the light turns green too late and the cars have to stop:
On the other hand, the InfluenceNet agent is able to anticipate that a car will be entering the local region and thus switch the lights just in time for the cars to continue without stopping:
At AAMAS: Deep learning of Coordination…?
Can deep Q-networks etc. brute force their way through tough coordination problems…? Perhaps not. Jacopo’s work, accepted as an extended abstract at AAMAS’19, takes a first step in exploring this in the one-shot setting.
Not so surprising: “joint Q-learner” can be too large/slow and “individual Q-learners” can fail to find good representations.
But good to know: “factored Q-value functions” which represent the Q-function as a random mixture of components involving 2 or 3 agents, can do quite well, even for hard coordination tasks!